« Philippe Creux
Snapshot testing with dbt
05 Nov 2023
I really enjoy building data warehouses using dbt.
dbt is a simple framework to define data transformation using plain SQL. We use it to transform data from our operational databases into tables for our datawarehouse.
Our dbt project can target both Postgres and BigQuery. This enables us to build the datawarehouse locally on Postgres. While we can quickly verify that the SQL syntax is valid, testing the correctness of the resulting dataset is a manual step.
dbt comes with a minimal testing framework to detect missing or duplicate entries but I find it insufficient make changes to the code with confidence. I didn’t have much success finding alternatives to dbt built-in tests so I decided to write unit tests. It didn’t take long to realize that writing unit tests to validate 100+ models would be quite tedious. Moreover, in my experience, the most common errors are due to changes in unrelated models so I needed something to help me quickly see that something was off without much effort.
I decided to give a try to using snapshot tests and it’s been of a great help so far!
Snapshot tests involve capturing the output and manually verifying it. It’s often used to detect unexpected user interface changes. Here, the output is the collection of tables created by dbt and their data.
We store the data in yaml files and check it in our GitHub repository. This allows us to verify visually that the expected changes are happening and spot any regression.
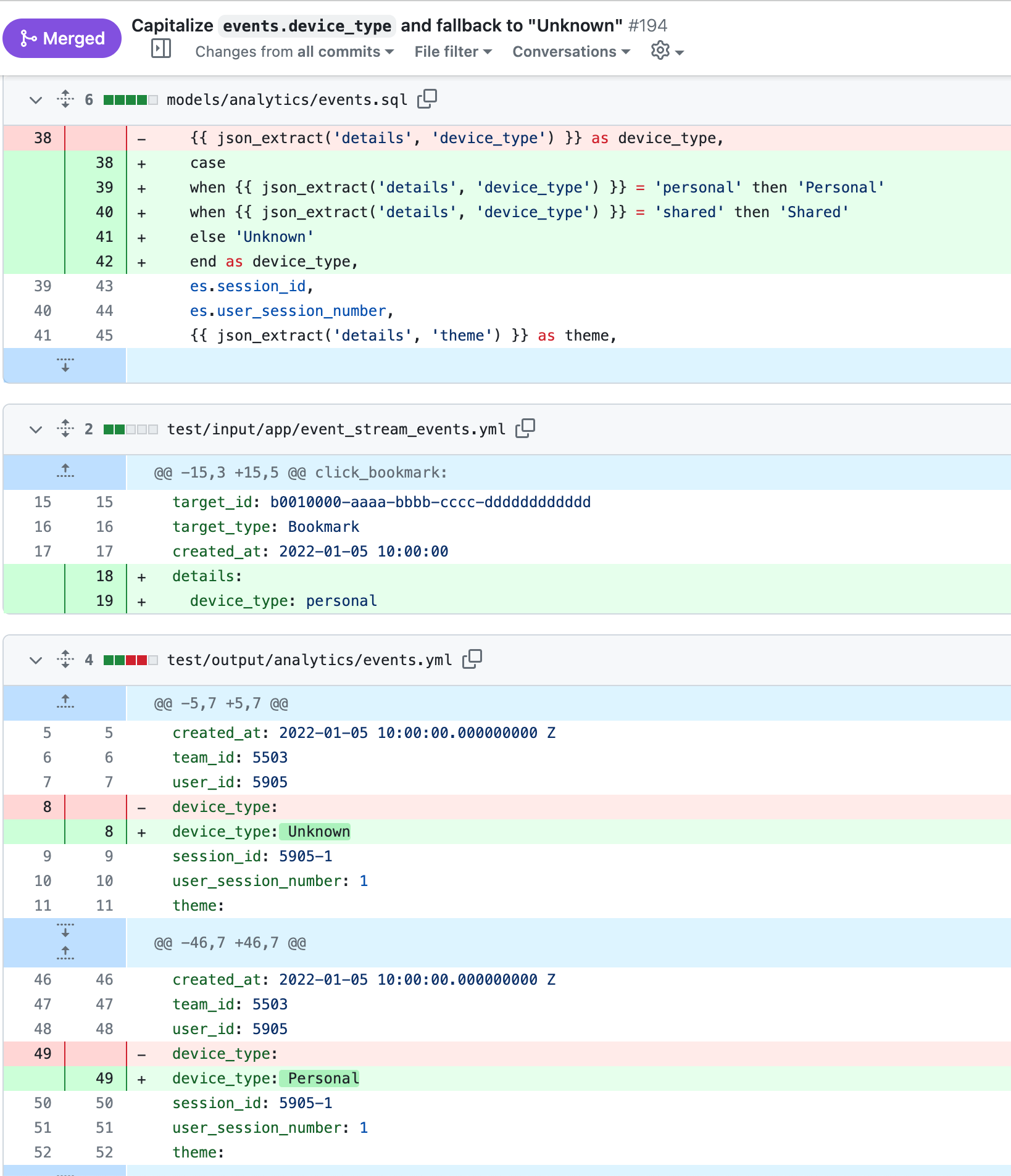
Here is a screenshot from a pull request where we’re making a change to capitalize the string device_type and fallback to "Unknown" instead of leaving it blank.
model/analytics.events.sqlis a dbt modeltest/input/app/event_stream_events.ymlis a yaml dump from the operational databasetest/output/analytics/events.ymlis a yaml dump from the datawarehouse model
How does it work?
Our dbt models can target both Postgres and BigQuery so that we can build the data warehouse locally on Postgres.
The data warehouse is built from a handful of application databases. On production, these are synced over to BigQuery.
When we perform a full test run, the following happens:
- we load the database SQL schema as individual Postgres schemas
- we load input data from yaml files into these schemas
- we run dbt locally
- we dump the resulting (output) schemas in yaml files
Here is an example:
test/
schemas/
app_1_db.sql
app_2_db.sql
input/
app_1_db/
table_1.yml
table_2.yml
app_2_db/
table_1.yml
output/
dataset_1/
model_1.yml
dataset_2/
model_1.yml
test/schemas
These are simple postgres dumps from the source databases. We regularly update them as the application databases get changed. We follow the convention where the name of the file is the name of the postgres schema.
input/SCHEMA/TABLE.yml
These yaml files contain the data for the given schema and table. Here is an example:
# input/app_1_db/users.yml
john:
id: 1
name: John
birthdate: 2000-01-01
created_at: 2018-01-01
sam:
id: 2
name: Sam
birthdate: 2000-01-08
created_at: 2018-01-01
These files were manually exported from a demo database and curated to limit their size. Each table has anywhere between 1 to 10 records at the moment. These files are maintained by hand.
In order to keep the output stable, we define all attributes including ids. We also make the ids unique across tables to catch bad joins (ex: join users on users.id = team_id).
output/DATASET/MODEL.yml
These yaml files show the data of the tables created in the data warehouse in yaml files. Example:
# output/dw/users.yml
- id: user/1
name: John
birth_month: 1
birth_day: 8
created_at: 2018-01-01
- id: user/2
name: Sam
birth_month: 1
birth_day: 1
created_at: 2018-01-01
The records are sorted by id to keep the output files stable.
We are a ruby shop, so the tool is built in ruby and executed using rake (the ruby equivalent of make, ant, yarn, etc).
We keep the build & snapshot step snappy by skipping steps that don’t need to re-run. So we only load schema if the schema files have changed, we only load data if the data files have changed, and we only run dbt if the dbt files have changed (this is made possible because we materialize models as SQL views).
Fast feedback loop and increased confidence
When we make changes to the code, we always run rake instead of running dbt run so that we can check the snapshot diffs (git diff). Reviewing a diff is much quicker and easier than checking the result in a DB Client and it surfaces unintended consequences in other tables that we wouldn’t have seen otherwise. This fast feedback loop makes development much more enjoyable and we can push up pull requests with high confidence in the change we’re making.
Reviewing pull requests is also a breeze as we can review the snapshot alongside the code to validate the behavior change.
Now, this can only be possible by ensuring the input files contain a wide variety of combinations. When a change is not reflected in the output, we update the input files to make sure that the behavior is surfaced in the output files. When we run into a bug on production, the fix includes updates to the input files acting as a regression test.
The time spent writing and maintaining this small snapshot testing framework paid off in a couple of weeks as it sped up both our development and review process, and it lowered the amount of bug shipped to production.
We’re unlikely to release this tool as an open source project because it is writen in Ruby (dbt is Python!) and it is quite specific to our needs. I’m happy to answer any questions on Mastodon.
You might also be interested in: